After years of getting different ideas for self-indexing search using Firestore, I have finally reached a usable conclusion that doesn’t use too much space, allows typos, sorts by relevance, and works without a separate database.
TL;DR #
Adding full-text search capabilities to Firestore can be easy; it just requires your own index. The fuzzy index with soundex makes full-text searching possible with little headache.
Other Databases #
If you need advanced features, it is recommended to use an external database built for searching. However, I believe this is overkill for most apps, even large ones.
🤦Yes, Google, the biggest search engine in the world, recommends a non-google product for Full-Text searching.
Idea 1 - Arrays and Maps #
If all else fails, you can store keywords inside arrays and search for them with where clauses.
const db = getFirestore();
const q = query(
collection(db, 'posts'),
where('terms', 'array-contains', 'query')
);
For more on this:
Idea 2 - Character Hack #
Firestore has a hack that allows you to search for the first character of a value. You search for the word up until the end of the character set. I don’t understand why his works, but it does.
function startsWith(
collectionRef: CollectionReference,
fieldName: string,
term: string
) {
return query(
collectionRef,
orderBy(fieldName),
startAt(term),
endAt(term + '~')
);
}
📝 You can use \uf8ff or the character ~. Both of these are known for the last character in the utf8 dataset.
// THIS IS THE SAME THING BTW
query(
collectionRef,
where(fieldName, '>=', term),
where(fieldName, '<=', term + '\uf8ff')
);
Usage #
const d = await getDocs(
startsWith(
collection(db, 'posts'),
'searchField',
'my-term'
)
);
☢️ Problems #
- You can’t search for the start of a word, only the start of a string.
- This will not work on maps or arrays.
However, this can be useful in certain situations.
Idea 3 - Trigram Fuzzy Search #
I built a trigram search once upon a time ago. I archived the package. It saves trigrams of a word in an array for searching. Imagine elon musk baseball:
// could be stored as array or map
[elo, lon, mus, usk, bas, ase, bal, all]
Then, you would search by using where clauses for each trigram or array-contains-all.
where('elo', '==', true),
where('lon', '==', true)
☢️ Problems #
Just like in all databases, trigram indexing is slow and painful. You also must convert each search phrase to a trigram for searching, as your query gets complex.
Idea 4 - Every Character Index #
You could index your array or map to contain any iteration of the word for searching. Let’s say you want to store elon musk in a title.
['e']
['el']
['elo']
['elon']
['elon ']
['elon m']
...
☢️ Problems #
- You need to index every letter manually with repeated information. Imagine if you had a paragraph of text!
Solution #
We can build on these ideas and group the text in clusters. No one will search for a whole paragraph; they will search for a few words at a time.
const NUMBER_OF_WORDS = 4;
const createIndex = (text: string) => {
// regex matches any alphanumeric from any language and strips spaces
const finalArray: string[] = [];
const wordArray = text
.toLowerCase()
.replace(/[^\p{L}\p{N}]+/gu, ' ')
.replace(/ +/g, ' ')
.trim()
.split(' ');
do {
finalArray.push(
wordArray.slice(0, NUMBER_OF_WORDS).join(' ')
);
wordArray.shift();
} while (wordArray.length !== 0);
return finalArray;
};
This will strip out all non-alphanumeric characters and make an array based on the words in groups of 4. For example, this text:
- Baseball is a game of strategy and skill, where every pitch, swing, and catch can change the course of the game in an instant.
We would have something like this:
["baseball is a game"],
["is a game of"],
["a game of strategy"],
["game of strategy and"],
["of strategy and skill"],
...
This does not help us, as we need to be able to search as we type the word. So, again, we must go through every iteration of that iteration.
for (const phrase of index) {
if (phrase) {
let v = '';
for (let i = 0; i < phrase.length; i++) {
v = phrase.slice(0, i + 1).trim();
// increment for relevance
m[v] = m[v] ? m[v] + 1 : 1;
}
}
}
And we end up with something like this:
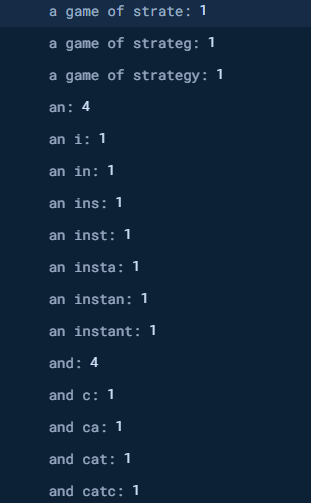
Relevance #
Instead of an array, we store it as a map. Notice the number by the word. Luckily, we don’t have to store repeated phrases like “and.” We can increment the value for each repetition of the words. This gives us relevance.
Searching #
To search, we find where the search field is equal to searchField.term. Since we are ordering by this also, we don’t need a where clause.
const data = await getDocs(
query(
collection(db, 'posts'),
orderBy(`searchField.${term}`),
limit(5)
)
);
Fuzzy Search #
What we really want is not an exact search but a fuzzy search. We need some kind of typo tolerance.
Typo Tolerance with Soundex #
The soundex algorithm has been used for years to simulate typo tolerance. It allows you to store text as sound patterns, not just as text.
// Take any string, and return the soundex
export function soundex(s: string): string {
const a = s.toLowerCase().split("");
const f = a.shift() as string;
let r = "";
const codes: Record<string, number | string> = {
a: "",
e: "",
i: "",
o: "",
u: "",
b: 1,
f: 1,
p: 1,
v: 1,
c: 2,
g: 2,
j: 2,
k: 2,
q: 2,
s: 2,
x: 2,
z: 2,
d: 3,
t: 3,
l: 4,
m: 5,
n: 5,
r: 6,
};
r = f + a
.map((v: string) => codes[v])
.filter((v, i: number, b) =>
i === 0 ? v !== codes[f] : v !== b[i - 1])
.join("");
return (r + "000").slice(0, 4).toUpperCase();
}
📝 There are different versions for different languages. Here is one for French, for example.
Using this pattern, we can slightly modify our storage mechanism to translate for soundex first.
const temp = [];
// translate to soundex
for (const i of index) {
temp.push(i.split(' ').map(
(v: string) => soundex(v)
).join(' '));
}
index = temp;
// add each iteration from the createIndex
for (const phrase of index) {
if (phrase) {
let v = '';
const t = phrase.split(' ');
while (t.length > 0) {
const r = t.shift();
v += v ? ' ' + r : r;
// increment for relevance
m[v] = m[v] ? m[v] + 1 : 1;
}
}
}
The beauty of this is it greatly simplifies your storage.

You’re only storing the sound itself, not the letters, and there are fewer iterations of sounds than words.
Remember to translate the text to soundex before you search as well!
// get the soundex terms
const searchText = text
.trim()
.split(' ')
.map(v => soundex(v))
.join(' ');
// search
const data = getDocs(
query(
collection(db, 'posts'),
orderBy(`search.${searchText}`),
limit(50)
)
);
💵 This is simpler and faster than Vector Search!
🤷 I have archived my j-firebase package, as I lack time to keep up with a repo.
📝 For an extra idea, you could also theoretically add stop-words, and ignore indexing them.
Backend or Frontend #
In practice, you should build a trigger function on each document creation for your collection to handle this indexing. The second best option is to use a backend function to add the data simultaneously. Technically, you can do this on the frontend with no problem, but offloading the generation to the backend makes more sense.
Demo: Vercel Serverless
Repo: GitHub
J