When you want to model your data in NoSQL, you must consider collections as your starting point. What are you showing on your website? You may not realize that you use the same old patterns repeatedly. Once you understand the building blocks of Cloud Firestore, you will learn the best practices for using them. However, ultimately, it is up to you and your data to determine the best structure.
TL;DR #
Collections exist only in a document’s path, not standalone. However, they are also necessary to create manual and automatic indexes for documents and to group and filter them. Use lowerCamelCase in field names and the plural case for collection names. Document IDs are good for enforcing unique names. Keep maps and arrays one level deep, or filtering will be impossible. Multiple nested layers are ok when you are aggregating data. You must aggregate data as your app becomes complex due to the costs or reading documents.
What is a NoSQL Collection? #
Think of a collection as a file folder holding your files. A folder holds documents, and so does a collection. The first collection you will usually create is a user's collection. Each document will be a user, and each user ID will be stored as the document ID.
users / 629hbXyE5NUVKaEr205oYZjaYbf2
{
"displayName": "Jonathan Gamble",
"email": "[email protected]",
"photoURL": "https://example.com/profile/image.png",
"username": "jdgamble555",
}
💪🏻 Best Practice #
- The standard in NoSQL is to use the plural form when naming a collection.
- When saving the user information, use the same variable names
displayName,email,photoURL,emailVerified, andphoneNumber. Most fields use the lowerCamelCase naming convention. - It is also expected to save your dates as
createdAtandupdatedAt. The user ID will usually be shortened touid. You could equally save the author and editor of a document ascreatedByandupdatedBy.
Note: SQL usually uses snake_case since it can’t detect capitalization without string quotes, which is an extra step.
Document ID #
All documents have a unique ID. You cannot have two documents with the same ID. When you fetch documents, you fetch them by their ID. A document ID is generated automatically on the client before creating a new document on the server. If you provide one, you can choose the document ID you want.
Subcollection #
A subcollection is another collection inside of a document. It is a collection nested inside of a document. The root level has to be a collection; collections can only have documents, and documents can only have subcollections. This means you can’t put documents directly inside documents or collections directly inside collections. The structure must be collection ➜ document ➜ subcollection ➜ document. This can keep going up until 100 subcollections. I do not recommend more than three layers deep ever, personally.
Document Path #
The document path is the full path to the document ID. In this case, it would be users/629hbXyE5NUVKaEr205oYZjaYbf2. If you had images, it could look like users/user_id/images/image_id. Each user could have infinite photos.
Storage Limits #
You can have as many collections or documents as you want. However, you can only store up to 1MB of information per document. This is one of the most important limits to consider, as it determines if you need a separate collection to store certain items. If you have 20 or more items, consider a separate collection.
For SQL Users #
If you use Cloud Firestore for the first time, collections are the tables. They will usually be in denormalized form, aggregated instead of using joins, and you don’t have to worry about a schema. A document ID would be the primary key.
Basic Structure #
After creating a users collection, you need to figure out the primary entity of your app. If you post tweets on X, you will want a tweets collection. You will want a jokes collection if you show jokes on a joke website. If you have a blog, you will want a posts collection. You will want a todos or tasks collection if you have a todo list. Whatever your app is principally storing, whether it be notes, reviews, cards, lists, or cars, make this a collection.
Subcollection or Collection #
You have some artistic leeway in organizing your data. It doesn’t matter how you organize data except in rare circumstances; nevertheless, some ways make better sense than others.
Could I use one Collection? #
You could technically use one large collection with subcollections for everything you want to store, but this would be odd. You could easily do users/user_id/tweets/tweet_id or users/user_id/posts/post_id, and it won’t affect anything.
💪🏻 Best Practice #
The best practice is to put your main entities at the root and put your secondary entities as subcollections. Your main entities would be collections like users, posts, or tweets, while your secondary entities could be comments, likes, or reviews. However, if reviews are the main focus of your website, they could also be placed at the root.
Field Uniqueness #
If you want to enforce that a field is unique, you need to duplicate the field key name as a document ID of a separate collection. Since a document ID is unique in every collection, this enforces uniqueness. For example, you could have a usernames root collection to enforce uniqueness while storing the actual username principally in the user’s document. You would also need Security Rules and batching. I will get into this later in another post and link it here.
Action Uniqueness #
When you need to enforce that something is unique for two entities, it is better to use subcollections. For example, a user can only like a post once. Storing it as a subcollection like posts/post_id/likes/user_id is better. Since you cannot add two documents to the same collection with the name as your user_id, a user cannot like a post more than once. The alternative would be to use a composite key on a root collection that would look something like this post_id__user_id, which is ugly and madness. Luckily, we don’t need all that nonsense now that we have Collection Group Queries.
Meta Collections #
There may also be situations where you want to store metadata about each collection. A unique collection that keeps track of unique values for a field would be a meta collection. If you wish to store totals, like the total number of items in a collection, you could use the _counters collection, where a document would be the collection's name. If you want to store data about your app in general, you could use a _meta collection and a good name like “statistics” for the document ID, depending on your data. I personally like to use an _ underscore to differentiate between normal collections and meta collections.
Data Types #
Firestore has 12 data types. You will see these types if you create a dashboard field.
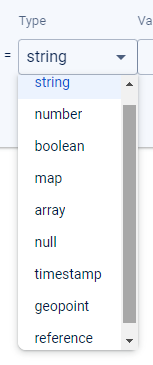
However, if you post data manually from a set or add operation, you could specify a floating number or an integer. You could add a bytes for storing image data or NaN for not a number.
💪🏻 Best Practice #
- Use maps only to store aggregation data or array data for filtering. Otherwise, use a separate collection. Don’t go more than one nested level.
- Save the current date and time using the
serverTimestamp()method. This ensures the date is taken from the server date instead of a random client’s date and time.
Filtering #
Firestore has many new methods for filtering, including or clauses. Firebase Realtime Database could not filter by more than one value at a time, so you had to create a manual composite index. Firestore can do most of this behind the scenes.
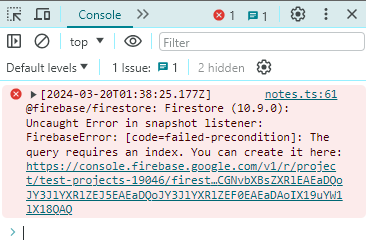
Indexes #
You often have to create a manual index when you use complex filters or order your query. If your client doesn’t show any data in development mode, look at your console.log. It will automatically generate a link to create the index you need. Otherwise, it would be difficult to understand the indexes manually.
Reading #
Learning data modeling in Firestore is slightly different from learning data modeling in other NoSQL databases. Not only do you need to understand the limits of queries and the need for denormalization and aggregation, but you must always keep the price of reads in mind. You are billed by every read and write, not by total data usage like in Firebase Realtime Database or other databases. Not only will it be slower to query more documents, it will cost you more. Good data modeling is a necessity, not just an art.
J