With the AI revolution, Vector Databases have become popular. Almost every big database that didn’t already have the option has added Vector support, and Firestore is no different. This demo was incredibly tedious and difficult to build; I will try to simplify it and show you what I learned.
TL;DR #
While Vector Search adds a type of full-text search support to your app, you must create an embedding for every search term before searching. This can be slow and cumbersome. The Vector Search is really just a document sort, and not a filter. However, it is very powerful and pretty cool in my book.
Vector Setup #
- Enable the Vector AI API in Google Console.
- Get a Firebase Admin Private Key and add it to your
.envfile. - Add Vertex AI Administrator to the Firebase IAM account you just generated.
- Install Firebase Admin for NodeJS
npm i -D firebase-admin
For non-Node environments, you must use the Firebase REST API instead.
- (Optional) Install Vertex AI for NodeJS
npm i -D @google-cloud/aiplatform
I have also included the REST API version, which I find more intuitive in this case.
Firebase Admin Setup #
Depending on your Framework, this could vary a bit, but the premise is the same.
import { PRIVATE_FIREBASE_ADMIN_CONFIG } from '$env/static/private';
import { getApps, initializeApp, cert, getApp } from 'firebase-admin/app';
import { getAuth } from 'firebase-admin/auth';
import { getFirestore } from 'firebase-admin/firestore';
const firebase_admin_config = JSON.parse(PRIVATE_FIREBASE_ADMIN_CONFIG);
// initialize admin firebase only once
export const adminApp = getApps().length
? getApp()
: initializeApp({
credential: cert(firebase_admin_config),
projectId: firebase_admin_config.project_id
});
export const adminAuth = getAuth(adminApp);
export const adminDB = getFirestore(adminApp, 'firestore-testing');
Notice I am using firestore-testing as a secondary database. We import the key from the .env file created before.
Embeddings #
The key to Vector Search is generating embeddings before storing data and searching for data. Unfortunately, this means you must make two API calls every time you search. One call will translate the data from your query text, and another will be used to search the Firestore database.
Vertex AI Model #
You can use OpenAI or any other LLM, but Google already has a model ready for text searching.
| English models | Multilingual models |
|---|---|
textembedding-gecko@001 | textembedding-gecko-multilingual@001 |
textembedding-gecko@003 | text-multilingual-embedding-002 |
text-embedding-004 | |
text-embedding-preview-0815 |
For English, the recommended model is text-embedding-004.
Task Type #
You also must select how you’re storing the data in the embedding.
| Task Type | Description |
|---|---|
SEMANTIC_SIMILARITY | Used to generate embeddings that are optimized to assess text similarity |
CLASSIFICATION | Used to generate embeddings that are optimized to classify texts according to preset labels |
CLUSTERING | Used to generate embeddings that are optimized to cluster texts based on their similarities |
RETRIEVAL_DOCUMENT, RETRIEVAL_QUERY, QUESTION_ANSWERING, and FACT_VERIFICATION | Used to generate embeddings that are optimized for document search or information retrieval |
Because we want to build a full-text search, we will use SEMANTIC_SIMILARITY. However, RETRIEVAL_DOCUMENT or RETRIEVAL_QUERY could also work for this use case. I tested those as well, and there is not much difference.
Dimensionality #
What is the quality of the Vector you want to store? The higher the quality, the more space you will use in Firestore. While the docs say a number between 1 and 2048, The maximum allowable dimensionality for the best quality is 768.
Instances #
Both API versions take an array of instances to search for. You could ultimately use this search for more than one term at a time. However, this example only uses one instance and task type.
Vertex AI Package #
We need to generate the embeddings from our text. This version needs to use our Firebase Admin keys directly.
import { PRIVATE_FIREBASE_ADMIN_CONFIG } from '$env/static/private';
import { adminAuth } from '$lib/firebase-admin';
import { PredictionServiceClient, helpers } from '@google-cloud/aiplatform';
import type { google } from '@google-cloud/aiplatform/build/protos/protos';
const firebase_admin_config = JSON.parse(PRIVATE_FIREBASE_ADMIN_CONFIG);
const model = 'text-embedding-004';
const task = 'SEMANTIC_SIMILARITY';
const location = 'us-central1';
const apiEndpoint = 'us-central1-aiplatform.googleapis.com';
const dimensionality = 768;
export const getEmbedding = async (content: string) => {
const project = adminAuth.app.options.projectId;
const client = new PredictionServiceClient({
apiEndpoint,
credentials: {
client_email: firebase_admin_config.client_email,
private_key: firebase_admin_config.private_key
}
});
const [response] = await client.predict({
endpoint: `projects/${project}/locations/${location}/publishers/google/models/${model}`,
instances: [
helpers.toValue({ content, task }) as google.protobuf.IValue
],
parameters: helpers.toValue({
outputDimensionality: dimensionality
})
});
const predictions = response.predictions;
if (!predictions) {
throw 'No predictions!';
}
const embeddings = predictions.map(p => {
const embeddingsProto = p.structValue!.fields!.embeddings;
const valuesProto = embeddingsProto.structValue!.fields!.values;
return valuesProto.listValue!.values!.map(v => v.numberValue);
});
return embeddings[0] as number[];
};
Packages like firebase-admin usually automatically handle mapping the vector data, but this package was just as difficult to use as basic REST API. You have to map the fields manually and return the complex array correctly. Google Packages will automatically log errors to the console.
REST API Method #
Alternatively, call the REST API directly. Here, we can use our Firebase Access Token.
export const getEmbedding2 = async (content: string) => {
const project = adminAuth.app.options.projectId;
const token = await adminAuth.app.options.credential!.getAccessToken();
const url = `https://us-central1-aiplatform.googleapis.com/v1/projects/${project}/locations/us-central1/publishers/google/models/text-embedding-004:predict`;
const r = await fetch(url, {
method: 'POST',
headers: {
'Authorization': `Bearer ${token.access_token}`,
'Content-Type': 'application/json'
},
body: JSON.stringify({
instances: [
{
"task_type": task,
// you can also use "title" for RETRIEVAL tasks
"content": content
},
],
parameters: {
outputDimensionality: dimensionality
}
})
});
if (!r.ok) {
const error = await r.json();
throw error;
}
const response = await r.json();
const predictions = response.predictions;
if (!predictions) {
throw 'No predictions!';
}
// @ts-expect-error: You should make your own types in reality here
const embeddings = predictions.map(p => p.embeddings.values);
return embeddings[0] as number[];
};
Save Data to Firestore #
In this example, we save the content to the text field and the vector to the search field.
const embeddings = await getEmbedding(text);
await adminDB.collection('posts').add({
text,
search: FieldValue.vector(embeddings)
});
Retrieving Data #
When retrieving our documents normally, without searching, we want to exclude the Vector field, as it will not be serializable from the server, and we don’t need to download extraneous information.
const data = await adminDB.collection('posts').get();
// don't return actual vector, won't serialize
const docs = data.docs.map((doc) => {
const data = doc.data();
return {
id: doc.id,
text: data['text']
};
});
return {
docs
};
📝 Using the Firebase REST API, you can choose the fields you want to download, thus avoiding the vector altogether and saving on data transfer.
Create an Index #
Before searching, you must add a Vector Index. Currently, there is no way to do this outside of using the gcloud CLI. I could not even get that to work on my local machine. Luckily, it works as expected using the Google Cloud Shell. Hopefully, this will be fixed soon when it is out of alpha.
gcloud alpha firestore indexes composite create
--collection-group=YOUR-COLLECTION
--query-scope=COLLECTION
--field-config field-path=search,vector-config='{"dimension":"768","flat": "{}"}'
--project=YOUR-PROJECT-ID
--database="YOUR-DATABASE"
Replace YOUR-COLLECTION, YOUR-PROJECT-ID, and YOUR-DATABASE with the respected information.
⚠️ COLLECTION is not to be replaced or confused with YOUR-COLLECTION.
📝 You can also edit the dimension here for indexing if you want to change the default quality.
⚠️ Get rid of all new lines before using this command!
Searching #
To search, we use the findNearest method. Unfortunately, we must get an embedding even for the data to be searched.
const embeddings = await getEmbedding(text);
const data = await adminDB
.collection('posts')
.findNearest(
'search',
FieldValue.vector(embeddings), {
limit: 5,
distanceMeasure: 'EUCLIDEAN'
})
.get();
// don't return actual vector, won't serialize
const docs = data.docs.map((doc) => {
const data = doc.data();
return {
id: doc.id,
text: data['text']
};
});
return {
docs
};
searchis our Vector Field- Since all vector data is ultimately related, we limit our results to 5. Otherwise, we could potentially return all documents. This is required for a reason. Vector Search ultimately just sorts the data. You can only return a maximum of 1000 documents.
- We want to use
EUCLIDEANto measure the shortest distance for semantic search. However,COSINEandDOT_PRODUCTare also available for more advanced cases.
Pricing #
- Embeddings are charged $0.000025 per 1000 characters.
- Vector Search is charged one read operation for each batch of up to 100 kNN vector index entries read by the query.
Other Filtering #
You can also add any other filters except for inequalities. However, each filter will require a separate index.
Vector Limitations #
- Vectors only work on the backend. If you need frontend support, write a
WRITEtrigger function that creates the vector anytime a new document is added to your collection. However, you would still need a backend to convert the search text to a vector before searching. - For this reason, I’m not sure if it will ever be available on the frontend JS package. This is the worst part of the search. This also limits the ability to use real-time listeners.
Google needs to use TypeScript for its examples instead of pure JavaScript. This was one of my many issues, and the documentation was terrible. Nevertheless, we got er goin!
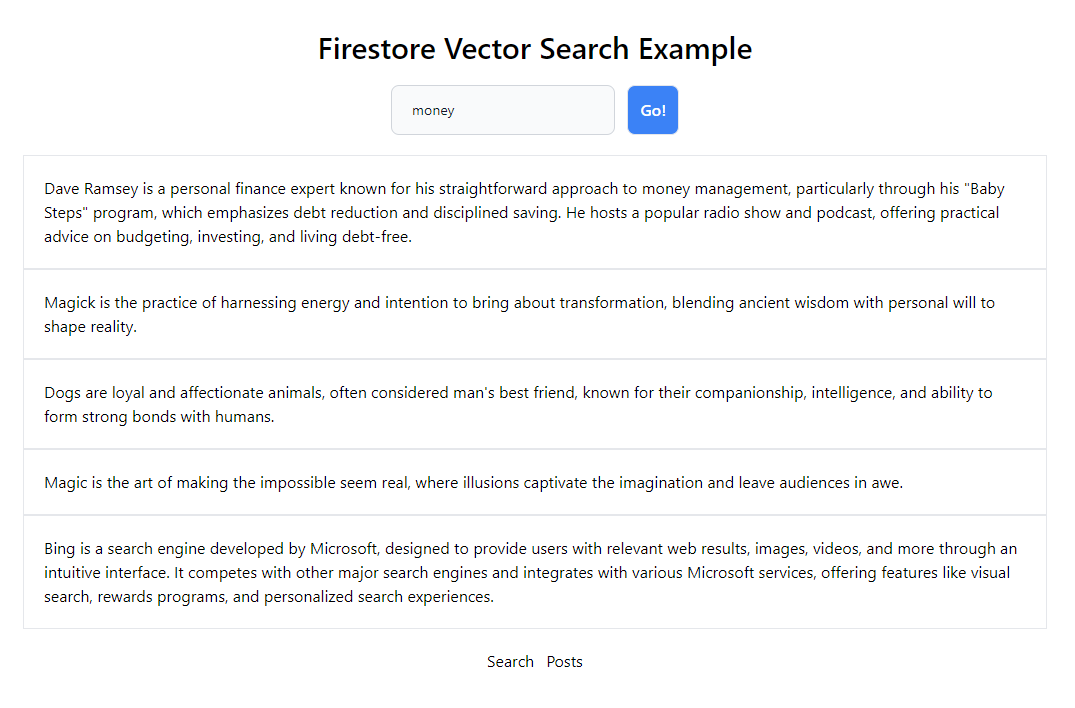
Demo #
- The demo uses SvelteKit with Form Actions.
- Searching for something may take 1-20 seconds. This is not ideal, but it varies consistently and is quick enough most of the time.
- I disabled adding new data to the production version to reduce spam.
Demo: Vercel Serverless
Repo: GitHub
J
Note #
I highly recommend you use the Fuzzy Full-Text Search instead of this one, as it is faster, smaller, and easier.