There are some situations in Firestore where you might hit a road block, especially in high traffic situations. Yes, I’m talking about writing to the same document in Firestore, not driving. Firestore has a limitation of 1 write per second. You may think this is not a big deal, but what if you get a lot of hits? High traffic actions or logging will cause writing to fail, so you must implement sharding to count database items correctly.
TL;DR #
| Method | ✅ Best For | ⚠️ Avoid When |
|---|---|---|
| Distributed Counter Extension | Counting views, counting high velocity likes, don’t need to keep track of each like | You don’t have more than one like per second, small sites, you need to keep track of information for each view or like |
| Distributed Counters + Server Sum | You want to define the number of shards beforehand (maybe up to 20 or so), you don’t want to spin up a schedule function every second | You don’t need to write more than once per second, you don’t want to read all items for an aggregation on client |
| Create Document + Server Count | You can just count the number of documents for a like, unique view, or action, and you need to store more information per action (IP address, user id, creation date, etc) | You don’t want to have your database overflown with lots of data you don’t need. An external API makes more sense (Google Analytics etc) |
Popular Examples #
Counting Views #
Imagine you want to count the number of views or hits your website gets. Even if your website does well, reaching a one second maximum is not going to be a big problem. However, imagine you’re selling the last 100 tickets to the last Elvis concert on your website and tickets start to be on sale at five o’clock. Your website might receive hundreds of new visitors a second, and you need to be able to accurately count them. Writing, or logging the views to the database more thane once a second will be problematic.
Counting Likes #
You just got on to the latest social media app. Taylor Swift just posted the funniest joke about football. Thousands of people go to like that post. You must implement a way to write more than one post a second so that she can accurately get her thumbs up, hearts, or [insert x action here].
Incrementing with Sharding #
This is where shards come in. A shard is a piece of a whole object; in this case a counter. If we can break our counters into X counters, we can have the ability write more than once a second. Distributed counters are documents that hold a count variable that can be incremented or decremented. To count all of them, we simply add up all of the shard count variables in each document.
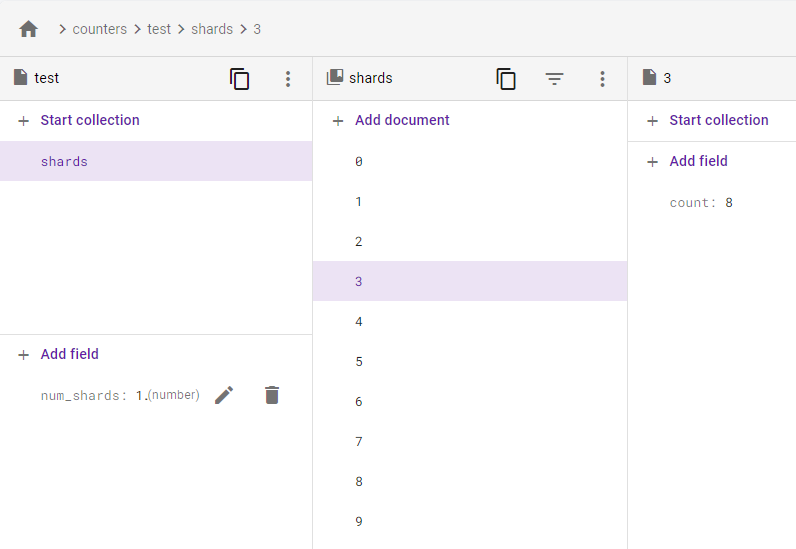
Create a Shard #
The Firebase website doesn’t have any update to date examples, so I modified them. First we must create a shard using batch. Here we are calling the counter test.
// define globals
const NUM_SHARDS = 10;
const ref = doc(db, '_counters/test');
async function createCounter() {
const batch = writeBatch(db);
// Initialize the counter document
batch.set(ref, { num_shards: NUM_SHARDS });
// Initialize each shard with count = 0
for (let i = 0; i < NUM_SHARDS; i++) {
const shardRef = doc(db, `${ref.path}/shards/${i.toString()}`);
batch.set(shardRef, { count: 0 });
}
// Commit the write batch
return batch.commit();
}
This should only be run once. Our structure will be counters/test document containing:
{
num_shards: 10
}
And we shall have counters/test/shards/0 containing:
{
count: 0
}
There will be 10 shards in this case. How many you need varies. Quoting Firebase:
With too few shards, some transactions may have to retry before succeeding, which will slow writes. With too many shards, reads become slower and more expensive.
However, I believe this was written before the latest Firebase 9 changes and the aggregation functions as we shall see.
Increment the Count #
In order to increment the count, we must find a random shard document, and increment that document.
export async function incrementCounter() {
// Select a shard of the counter at random
const shard_id = Math.floor(Math.random() * NUM_SHARDS).toString();
const shard_ref = doc(db, `${ref.path}/shards/${shard_id}`);
// Update count
await updateDoc(shard_ref, "count", increment(1));
return getCount();
}
This minimalist example by Firebase does not actually retry anything. You could have a try and catch block to keep trying different shards in case of a problem, or you could put the update in a transaction, which will automatically retry. In reality, if you fail, you need more shards.
Getting the Total Count #
In order to get the total count, you need to add up all the individual shards (all count values in the shards subcollection). For my test app, I create the counter for the first time if it doesn’t exist.
export async function getCount() {
// create couter if doesn't exist
const docRef = await getDoc(ref);
if (!docRef.exists()) {
await createCounter();
}
// Sum the count of each shard in the subcollection
const snapshot = await getDocs(collection(db, `${ref.path}/shards`));
let total_count = 0;
snapshot.forEach((doc) => {
total_count += doc.data().count;
});
return total_count;
}
Now obviously this is a minimalist example. This would require 10 reads for each count every time you update a document. Luckily there is a more modern way.
Server Count #
const snapshot = await getAggregateFromServer(
collection(db, `${ref.path}/shards`), {
totalCount: sum('count')
});
return snapshot.data().totalCount;
We can also use the sum aggregator to get the total instead of manually calculating it. This is not available as an observable, but it could be added to our app in a way that refetches when necessary.
Security #
And we need to secure it by making sure you can add the counters, and only increment them by one.
match /databases/{database}/documents {
function isIncrement() {
return request.resource.data['count'] == resource.data['count'] + 1;
}
match /_counters/{document} {
allow read, create;
}
match /_counters/{document}/shards/{shard} {
allow read, create;
allow update: if isIncrement();
}
}
Other Additions #
You could use this code in production. However, you may want to use a schedule function to add them up ever minute, or you may want this code server side. You also could use RXJS if you wanted to count 10-20 posts changes at a time (although not recommended). Ultimately, you would probably keep the core concept and adapt it to your exact situation.
Distributed Counter Extension #
All of this really should be done on the backend. Luckily, Firebase built the Distributed Counter extension. This will schedule tasks or workers that keep the counter up to date. It manually adds all of them up (not using aggregate functions). It has not been updated since aggregate functions were released, and I’m not sure if it ever will be. The extension is class based that will scale the counters for you automatically. It could get more costly, but it has been battle tested.
Create Documents Instead #
The real reason distributed counters are needed is that you can only write to one document once per second. Personally, I’m not a fan of using increment to track anything that matters. In practice, it may just make more sense to create a document for each count, then add them up with a server count. We usually need to keep other data along with it in practice.
Unique Views #
If we want to track something like unique views, we would need to keep track of IP addresses. In that case we could create a document where the document ID is the IP address (or the day and IP address etc), and don’t allow duplicates. We could aggregate the number of documents in that collection to get the total unique visits. There are no increments necessary because we don’t need to keep track of the count manually.
Likes #
The same goes for likes. Usually we will only want a logged in user to like a post. We simply keep track of the likes in a collection, and aggregate the number of documents. Of course this all depends on if we need realtime updates, unique likes, and we don’t mind creating more documents. If we need to sort by the likes, we will want to save the total somewhere as well.
Either way, the concept of distributed counters is something you need to understand before you build a high traffic app in Firebase.
Example App #
You can spin up this repo using Firestore Emulators.
Repo: GitHub